For tasks like object or speech recognition we know that all the information required to successfully perform the task is encoded in the raw data. Humans can perform these tasks from the raw data for example.
However, natural language processing systems traditionally treat words as discrete atomic symbols, and therefore ‘cat’ may be represented as Id537 and ‘dog’ as Id143.
These encodings are arbitrary, and provide no useful information to the system regarding the relationships that may exist between the individual symbols.
This means that the model can leverage very little of what it has learned about ‘cats’ when it is processing data about ‘dogs’ (such that they are both animals, four-legged, pets, etc.).
Representing words as unique, discrete ids furthermore leads to data sparsity, which means more data is needed in order to successfully train statistical models.
Vector representations of words (word embeddings) can overcome these obstacles.

What are word embeddings?
Word embeddings is simply a vector representations of words.

Specifically, it is a vector space model (VSM) which represents words in a continuous vector space such that words that share common contexts and semantics are located in close proximity to one another in the space.
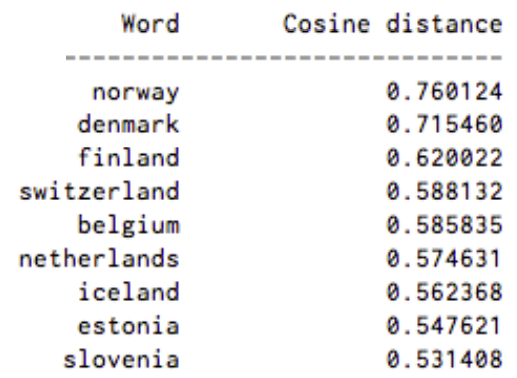
How to compute word embeddings?
There are 2 methods to compute word embeddings: count-based methods (e.g. Latent Semantic Analysis), and predictive methods (e.g. neural probabilistic language models).
All methods assume the Distributional Hypothesis, which states that linguistic items with similar distributions have similar meanings, more simply, words which appear in the same contexts share semantic meaning.
Count-based methods
Count-based methods compute the statistics of how often some word co-occurs with its neighbor words, and then map these count-statistics down to a small, dense vector for each word.
Predictive Methods
Predictive models directly try to predict a word from its neighbors in terms of learned small, dense embedding vectors (considered parameters of the model).
Traditionally, predictive models are trained using the maximum likelihood principle to maximize the probability of the next words given the previous words in terms of a softmax function over all the vocabulary words.
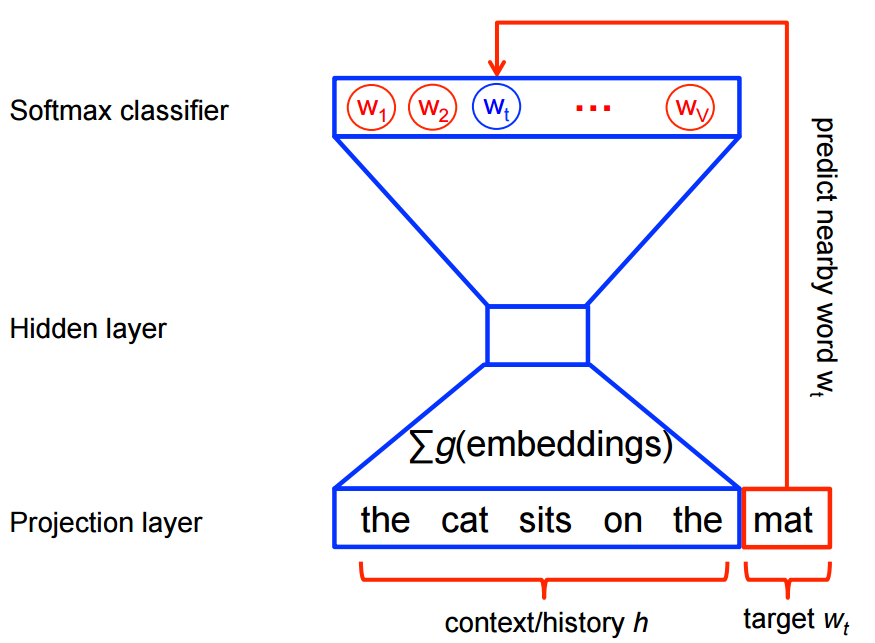
However, this training procedure is quite computationally expensive given a large vocabulary set, because we need to compute and normalize all vocabulary words at each training step. Therefore many models provide different ways of reducing computation.
Conclusion
Word embeddings contain the potential of being very useful, even fundamental to many NLP tasks, not only traditional text, but also genes, programming languages(seriously, has anyone tried that?), and other types of langauges.
We are just scratching the surface, I suggest you to check out my Word2Vec post for a great word embeddings example.