A storage engine is the underlying software component that a database management system (DBMS) uses to create, read, update and delete (CRUD) data from a database.
No Storage Engine is Perfect
There is no perfect storage engine, a certain storage engine may be very effective in certain operations and environments yet very ineffective in others. This is taken into consideration when picking which storage engines are best suited for the DBMS.
As a result many modern DBMS support multiple storage engines as a modular component within the same database. For example, MySQL supports InnoDB as well as MyISAM.
Data Structures
A data structure is an abstract format for organizing data. There are many data structures types, each form has its own particular advantages and disadvantages.
Similarily to storage engines - no data structure is perfect.
Which data structure the storage engine uses is a key attribute and defines much of which opeartions are effective and ineffective for that storage engine.
Two popular and interesting data structures used in storage engines are B+ and LSM trees, more on them later.
It should be no surprise that storage engines favour trees over other data structures:
- The data stored in trees is ordered hierarchically which is effcient to sort and search in a range.
- Trees scale well. They start small and can grow neatly to even enormous sizes. Unlike hashes which have a fixed size that can be too big or too small.
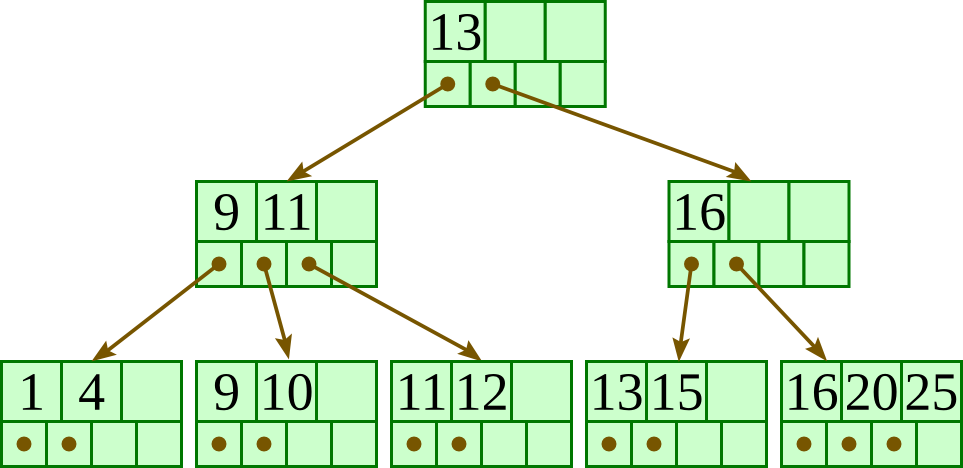
B+ Tree
Before jumping into B+ trees I suggest to read what B-tree is.
But for the most part B-tree is a tree such that each node:
- Has a number of values and child nodes within some pre-defined length.
- Contains a number of keys to separate values which divide its subtrees.
A B+ tree can be viewed as a B-tree in which each node contains only keys (without values), and to which an additional level is added at the bottom with all the values linked sequentially as leaves.
Another way to look at it is that in a B+ tree all leaves are at the same distance from the root.
More in-depth overview of B+ trees here.
LSM Tree
Log-structured merge-tree (LSM tree) is a mix between a data structure and an optimization algorithm, it is based on the fact that random operations are much slower than sequential ones, therefore random operations are to be avoided.
LSM trees achieve this by storing the data in RAM and disk separately.
Write operations are sequentially written to a log in RAM, all logs are immutable, new updates are written to new logs which leads to multiple logs for the same entry.
Read operations search for the latest log for a given entry. If an entry is not found then it is loaded from disk. Reads are not particularly fast in LSM trees because they are required to search through all the logs.
Logs of the same entry in memory are occasionally merged to allow for faster reads (less logs means less searching for read operations).
The LSM tree ocassionally syncs the data from RAM to disk as a sequential write, except of this write no other write is made to disk, as a result, there is always an agreement that RAM data is newer than disk data, this allows the LSM tree to sync data to disk by writing new files rather than modifying, which increases performance.

A more in-depth overview of LSM trees here.
Examples of Storage Engines
Here are 3 of my favorite storage engines: LevelDB, RocksDB and LMDB.
I’ll give a brief overview of each.
LevelDB

LevelDB is an open-source, on-disk, key-value store written by Google and inspired by BigTable.
LevelDB features include:
- Stores keys and values in arbitrary byte arrays.
- Sorts data by key.
- Supports batching writes.
- Forward and backward iteration.
- Compression of the data via Google’s Snappy compression library.
LevelDB is not an SQL database and like other NoSQL stores:
- It does not have a relational data model.
- It does not support SQL queries.
- It has no support for indexes.
Applications use LevelDB as a library, as it does not provide a server or command-line interface.
LevelDB uses LSM trees as its data structure, which means it performs much of the work in memory and occasionally syncs the data to disk. Writes are fast but reads are slow.
RocksDB
![]()
RocksDB was begun at Facebook in April 2012, as a fork of LevelDB and it’s open-source as well.
RocksDB is optimized for performance by efficiently exploiting many CPU cores, making efficient use of fast storage and more…
In terms of features, RocksDB provides all of the features of LevelDB(described above) along with a bunch of its own features, including:
- Column Families
- Bloom Filters
- Transactions
- Time to Live (TTL) support
- Universal Compaction
- Merge Operators
- Statistics Collection
- Geo-spatial
Generally, RocksDB is a much more upgraded version of LevelDB.
LMDB
Lightning Memory-Mapped Database (LMDB) is a highly-optimized transactional database in the form of a key-value store and features lightning-fast reads with good write performance.
B+ trees are LMDB’s data structure, which allows for faster reads and more effcient range-based search capability.
Some of its other notable features are:
- High-performance.
- Stores arbitrary key/data pairs as byte arrays.
- Supports multiple data items for a single key.
- Has a dramatic write performance increase when appending records at the end of the database.
- Scales well concurrently in multi-threaded or multi-proessing environments.
- Maintains data integrity inherently by design.
- Does not require a transaction log (hereby increasing write performance by not needing to write data twice).
In essence, LMDB is one beast of a database yet has a very small footprint. An engineering masterpiece.
Conclusions
Storage engines are fascinating. They are the work of very talented people who tackle some of the hardest problems in computer science to produce masterpieces of engineering which hold and take care of all of our data.
Storage engines are constantly evolving, as a response to better hardware, technology and experience.
I hope this post gave you a good introduction to storage engines and until next time, happy engineering.